System scaling in a multi-tier architecture

I've 3.5+ years of experience in software development and willing to share my knowledge while working on real-time IT solutions.
Introduction
A single server setup wherein everything runs only on one server i.e database, cache, session data etc has various disadvantages. It may result in a Single Point Of Failure(SPOF), and increased response time hence there is a need for scaling to distribute traffic coming to the server. To overcome this issue, modern systems make use of multiple servers and load balancing.
What is scaling?
Scaling is the process of adding more resources such as CPU, and RAM to your servers. Scaling can be of two types as follows:
Vertical Scaling: The process of adding resources on top of existing servers is called vertical scaling. It has a hard limit i.e it is not possible to add an unlimited amount of memory, and CPU to a single server. If one server goes down, the entire system goes down!
Horizontal Scaling: The addition of more servers to scale out the pool of resources is called horizontal scaling. Large-scale applications prefer horizontal scaling.
Building an efficient system
Before we proceed with a detailed description of the architectural design of a generalised system, let's take a look at the figure below.
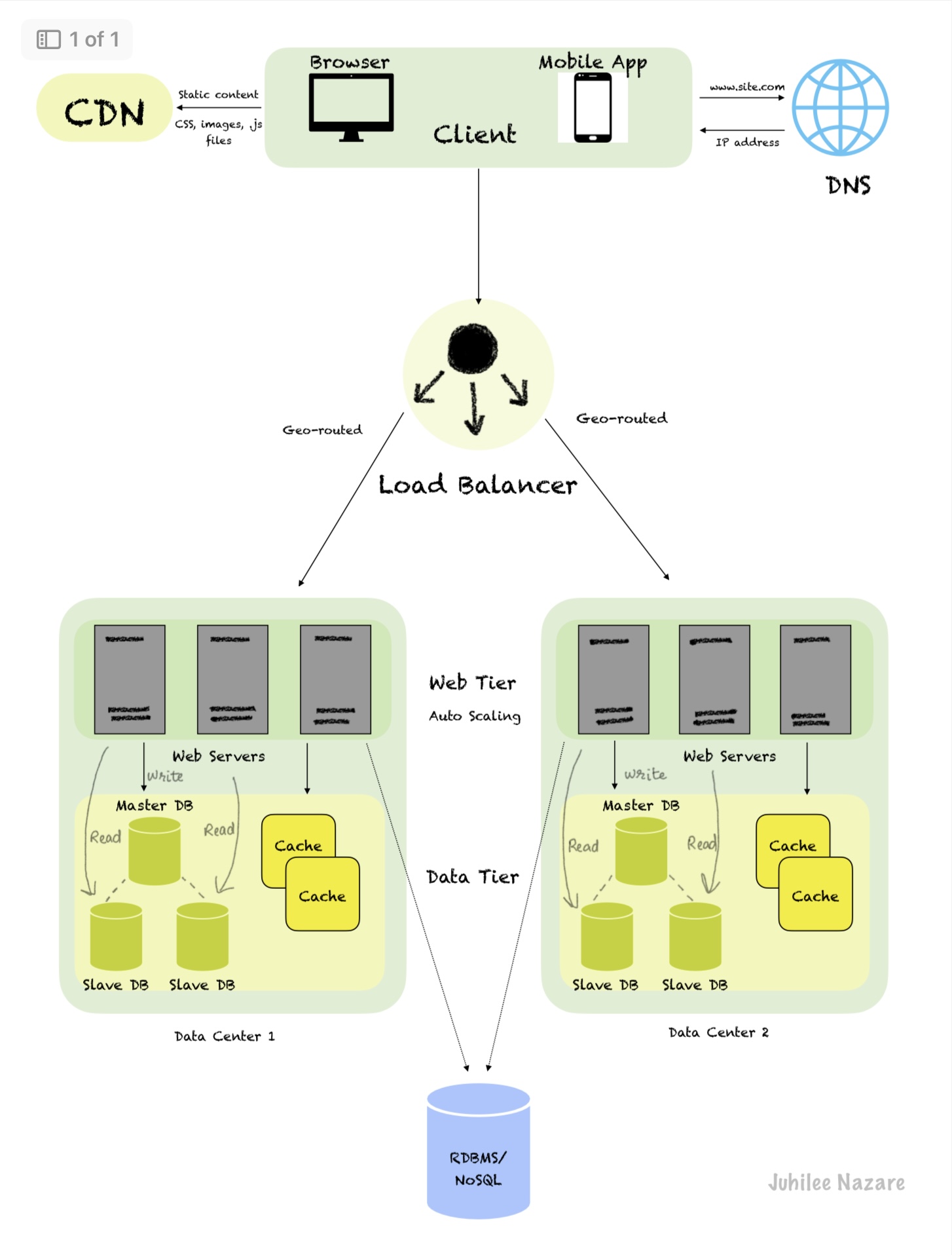
We'll explore individual components in the above image to simplify the design and it won't seem as complex as it is at first glance.
Client: A client or a user is the one that requests access to data and services provided by the server. A Client can be a web browser, mobile app etc.
DNS: It refers to Domain Name System, a directory service that provides a mapping between hostname and IP address. Every host/machine has an IP address for unique identification in a particular network. DNS converts the domain name of websites to their numerical IP addresses.
In the above figure, www.site.com will be converted to an IP address such as 192.18.90.1 (example).
Load Balancer: It evenly distributes incoming requests traffic among the web servers to avoid overloading and provide improved response time. If one of the web servers goes down, the entire website doesn't go offline. If traffic increases unexpectedly, you may scale up the web tier and the load balancer handles the situation gracefully by starting to send requests to the newly added server.
Web Tier: It comprises multiple web servers to which the client sends requests. However, with the introduction of a load balancer between the web tier and the client the web servers aren't directly reachable by clients instead the users connect to the local IP of the load balancer. The servers interact with each other and with the load balancer via private IP addresses which are reachable only between servers in the same network.
To avoid SPOF, the web tier supports auto-scaling and consists of multiple web servers.
Data Tier: To isolate the request traffic (web tier) from the database and allow independent scaling there are separate database servers. These databases can be relational such as PostgreSQL, MySQL, Oracle DB or non-relational such as Cassandra, HBase, Neo4j etc. Choosing the right database depends on the application requirements.
Database replication with master(original) and slave(replicas) relationship helps to provide better performance and high availability. Generally, a master will support write(insert, delete, update) operations whereas slaves are meant for read operations. Even if one of the databases is unavailable, your website remains in operation.
If there's only one slave and it goes down, all traffic will be directed to the master temporarily for read/write operations.
In case the master itself goes offline, a new slave will be promoted to master. However, this might include some complexities if the slave isn't in sync with all the latest write operations performed on the master. The missing data then needs to be updated by using data recovery scripts.
Cache: A temporary storage to store the results of frequently accessed data expensive responses so that the requests are served faster. It has a simple mechanism i.e if data exists in the cache, read data from the cache. If data doesn't exist in the cache, first save the data to the cache from the database and return the data to the web server.
To add new data to the cache once it is full, existing items must be removed and this is known as cache eviction. Various eviction policies such as Least Recently Used(LRU), First In First Out(FIFO) and Least Frequently Used(LFU) can be utilized in different use cases.
An expiration policy is associated with the cache to remove unwanted data. The duration should not be too short otherwise it results in pulling data from database frequently nor should be too long that the data becomes stale!
Content Delivery Network: It is a network of geographically distributed servers that cache and provide static content such as images, .js files, CSS etc. When a user hits a request, the closest CDN server delivers this static content. Its caching mechanism is the same as described above. For the data stored in CDN, there is an optional Time-to-Live(TTL) associated which defines the duration for which the static content is going to be cached.
Shared Storage: It is a good practice to session data separately in a shared relational or NoSQL database which is accessible to each web server in the web tier.
Data Center: A facility that consists of a pool of resources such as web servers, storage systems, routers and network security appliances such as firewall. There are multiple data centers geographically distributed and upon a request the user is geo-routed to the closest data center for serving the response. In the event of data center outage or maintenance activities, the traffic is directed to a new data center.
I hope this article provided you good insight on how scaling occurs across large scale applications to support millions of users with no downtime.




